UiPathにおけるデータ構造の選択は、自動化プロセスの効率と実行速度に直接影響します。
この記事では、List<T>型とHashSet<T>型の基本的な特性と、それぞれの処理速度の違いについて解説します。
Table Of Contents
ジェネリックコレクションクラス
まずジェネリックコレクションクラスについて説明します。
List<T>とHashSet<T>は「System.Collections.Generic」名前空間に含まれるジェネリックコレクションであり、厳密に型指定されたデータをまとめて管理するためのデータ構造となります。
コレクションクラス毎に特徴があるため、用途に適したデータ構造を選択する必要があります。
List<T>
List<T>は要素が追加された順番が保持されるため、インデックスを使用して任意のインデックスの要素にアクセスできます。
また、重複する要素を保持できるため、同じ値の要素を複数格納することが可能です。
List<T>の使用は、要素の追加・削除・およびリスト内の要素へのランダムアクセスが頻繁に行われる場合に適しています。
要素へのランダムアクセスを行う手順について、UiPathの画面を用いて説明します。
・Assignアクティビティをシーケンスに追加し、左辺に「lstFruits」、右辺に「New List(Of String) From {“Apple”, “Banana”, “Cherry”}」と入力し、List<T>を初期化します。
・LogMessageアクティビティをシーケンスに追加し、「メッセージ」に「lstFruits(2)」と入力します。

以上の処理を実装したシーケンスを実行した処理結果ログは以下になります。

このように、インデックスを角括弧内に指定することでリスト内の特定の位置にある要素にアクセスすることが可能となります。
※インデックスは0から始まることに注意して下さい。
HashSet<T>型
HashSet<T>は重複する要素を自動的に無視します。
同じ値を二度追加しようとしても、HashSet<T>には一度だけ追加されます。
また、内部的にハッシュテーブルを使用しているため、要素の検索がList<T>と比較して高速です。
他のHashSet<T>との和集合、積集合、差集合、対称差を計算する集合の演算メソッドを提供しており、ユニークな要素を抽出したり、逆に共通する要素だけを残すことも可能です。
HashSet<T>の使用は、一意の項目リストが必要な場合や、要素の存在のみが重要で、その順序や回数が問題ではない場合に適しています。
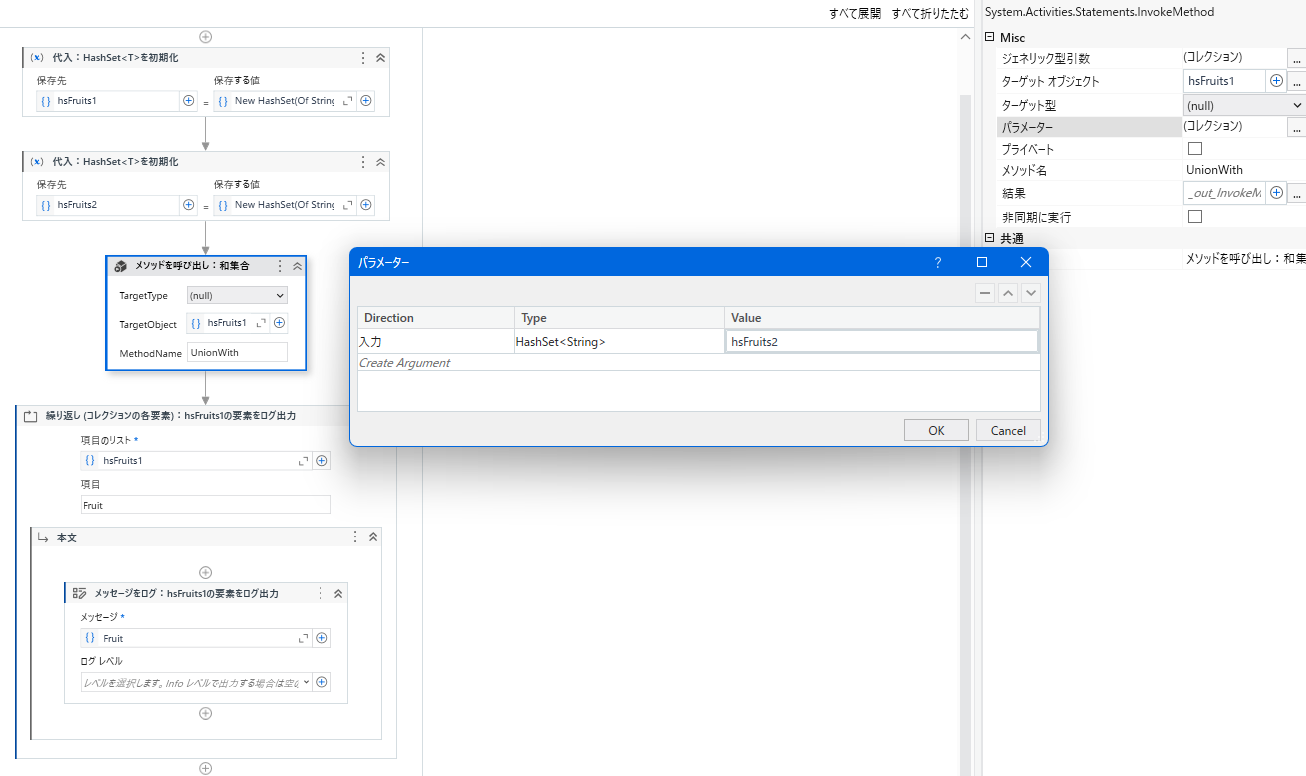
他のHashSet<T>との和集合を調査する手順について、UiPathの画面を用いて説明します。
・Assignアクティビティをシーケンスに追加し、左辺に「hsFruits1」、右辺に「New HashSet(Of String) From {“Apple”, “Banana”, “Cherry”}」と入力し、HashSet<T>を初期化します。
・Assignアクティビティをシーケンスに追加し、左辺に「hsFruits2」、右辺に「New HashSet(Of String) From {“Apple”, “Blueberry”, “Grape”, “Orange”}」と入力し、HashSet<T>を初期化します。
・InvokeMethodアクティビティをシーケンスに追加し、「TargetObject」に「hsFruits1」、「MethodName」に「UnionWith」ト入力し、パラメーターにHashSet<String>型の「hsFruits2」を指定します。
※集合の演算メソッドには戻り値が存在しないため、UiPathで集合の演算を行う際はAssignアクティビティではなくInvokeMethodアクティビティを利用する点に注意して下さい。
・ForEachアクティビティをシーケンスに追加し、「項目のリスト」に「hsFruits1」、「項目」に「Fruit」を入力します。
・LogMessageアクティビティをForEachアクティビティの中に追加し、「メッセージ」に「Fruit」と入力します。
以上の処理を実装したシーケンスを実行した処理結果ログは以下になります。
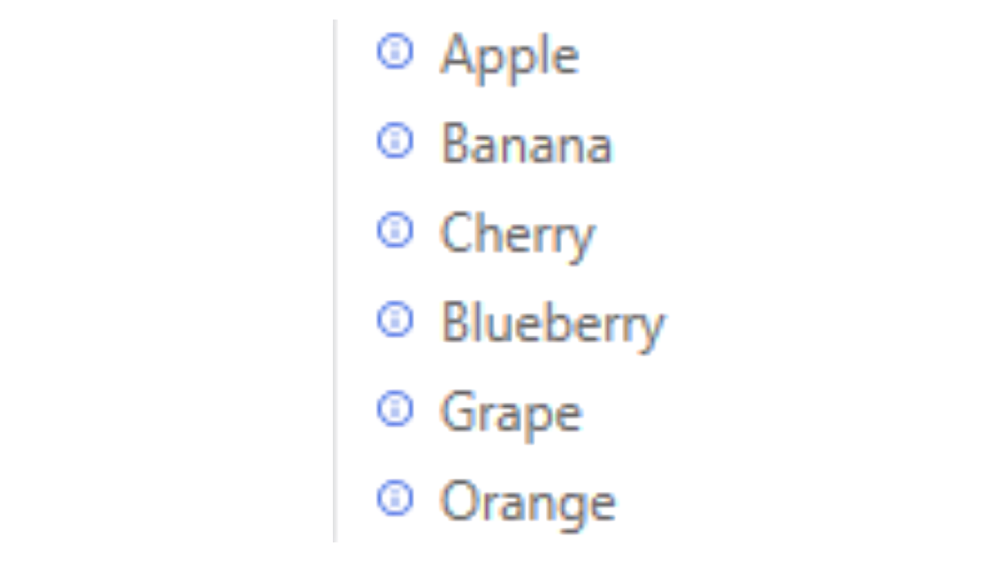
このように、HashSet<T>では他のHashSet<T>と集合の演算を行うことが可能となります。
まとめ
List<T>とHashSet<T>はそれぞれ異なる特性を持ち、プロジェクトにおけるデータ管理のニーズに応じて使い分けることが重要です。
適切なデータ構造を選択することで、自動化プロセスの効率性とパフォーマンスを向上させることができます。